나는 요즘 관계형 데이터베이스로 개발을 진행하고 있다. 근데 최근 들은 내용이 꽤 흥미로워서 기록으로 남겨보려고 한다.
관계형 데이터베이스에서의 PK
관계형 데이터베이스에는 여러가지 키라는 개념이 존재한다. 기본키, 수퍼키, 후보키 등이 존재하는데 여기서는 기본키(Primary Key)에 집중하려고 한다.
데이터베이스 교과서를 보면 PK를 다음과 같이 정의한다.
릴레이션 안에서 튜플을 구별하기 위한 수단으로 주 키(primary key)라는 용어를 사용한다.
릴레이션은 테이블을 튜플은 row를 의미하므로 PK는 곧 테이블 안에서 unique한 컬럼을 의미하게 된다. 그 중에서 가장 흔하게 사용되는 PK는 아마 auto_increment옵션이 붙어있는 integer일 것이다. 이는 데이터베이스 내부에서 자동으로 지정해주기 때문에 편리하고 공간도 적게 차지한다. 또는 "테이블 속성 + index number"로도 흔히 사용한다. 예를들면 order 테이블에 키를 "ORDER00001"같은 형식으로 사용한다.
이렇게 사용하는 것이 정답으로 알고 계속 사용해왔는데 이 방식의 문제점이 있을까?
Incremental PK의 문제점
의외의 문제점이 있었다.
위에서 소개한 PK방식은 수가 incremental하게 지정되기 때문에 id가 곧 row의 개수가 된다. 보통 클라이언트와 소통할 때 id로 PK를 자주 사용하므로 이 값은 클라이언트에게 노출이 될 것이다. 그렇게 되면 클라이언트 측에서 프로젝트의 규모를 유추할 수 있다는 뜻이 된다.

보통 규모를 유추해서 뭘 하겠냐마는 경우에 따라서는 치명적일 수 있다.
또한 이 정보를 url에 넣어 사용한다면 다른 값을 넣어 비정상적인 접근 시도를 할 가능성이 생긴다.
위 사진의 url에서 1234를 1235로 바꿔서 접속하면 다른 글을 볼 가능성이 생긴다. 물론 높은 수준의 접근제한을 걸면 해결 되지만 미처 처리하지 못할경우 문제가 생긴다.
다른 문제점으로 분산 DB에서 충돌이 일어날 수 있다. 예를 들어 사용자 이름을 기준으로 샤딩한 데이터베이스가 2개 있다고 하자. A~M은 DB1로, N~Z는 DB2로 저장을 하게 했다. increment하게 PK를 지정한다면 DB1과 DB2는 서로 상태를 모르기 때문에 자신의 row기준으로 번호를 지정할 것이다. 이 경우 쿼리의 결과에 PK가 중복될 수 있는 문제가 있다.
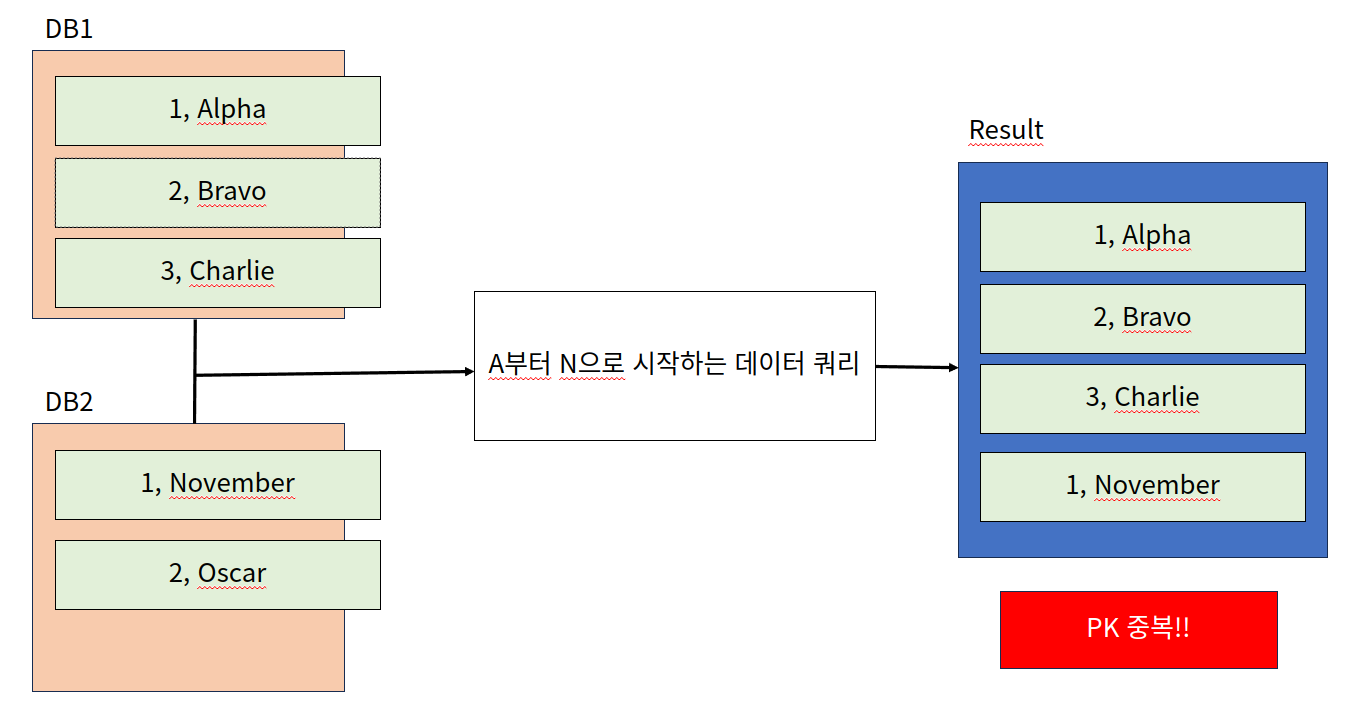
다음에 PK가 1인 데이터를 쿼리할 때 난감한 상황이 발생할 수 있다.
그렇다면 이 문제를 해결하기 위한 방법은 어떤게 있을까?
PK에서 UUID의 사용
최근 또 많이 사용하는 방식이 PK에 UUID를 사용하는 것이다. UUID는 고유하고 예측 불가능하기때문에 위에서 발생한 문제들을 모두 해결할 수 있다.
그렇다면 무조건 PK에 UUID를 사용하는 것이 정답일까?
UUID사용상의 단점
우선 int에 비해 저장 공간을 많이 차지한다. 이 말은 데이터 전송시에도 더 많은 양을 전송하게 된다는 뜻이다. JOIN할때도 int비교가 아닌 string비교가 되기 때문에 성능이 더 저하된다.
PK를 생성할 경우 자동으로 인덱스도 같이 만들어진다. RDB에서 인덱스는 보통 B+ Tree를 이용한 인덱스이기 때문에 인덱스를 활용하기가 매우 힘들다. "WHERE id < 10" 이었던 쿼리도 "WHERE id IN ('a5e4f12235d2', '6sdd5e1f32d')"이런식으로 작성하게 될 것이다. 같은 이유로 커서 기반 페이지네이션에 PK를 활용할 수 없다.
다만 해시기반 인덱스를 사용하는 NoSQL에는 해당되지 않는다.
결론
분산 DB를 사용할 때와 클라이언트에게 보여줄 데이터가 있는 테이블은 UUID PK를 사용하는 것이 좋다.
그리고 외부로 공개되지 않는 테이블과 공개하더라도 제한된 사용자만 사용하는 사이트(ex 백오피스)는 성능을 위해 Incremental PK를 사용하는것이 좋다.
다만 현재는 외부에 공개되지 않는 테이블도 나중에는 공개될 수 있으므로 이 점도 고려하는 것이 좋다.
즉, 보안성이 필요하고 일반적인 경우에는 UUID PK를 보안을 살짝 포기하더라도 성능이 더 중요하다면 Incremental PK를 사용하면 될 것 같다.
'프로그래밍 > 개발' 카테고리의 다른 글
| [개발] 제 1회 엘리스 코드 챌린지 참가 후기 (0) | 2023.12.16 |
|---|---|
| [개발] 주니어 개발자의 우당탕탕 MSA 전환기 - Nexus 편 (0) | 2023.12.13 |
| [개발] 주니어 개발자의 우당탕탕 MSA 전환기 - DB 편 (1) | 2023.09.04 |
| [개발] Redis를 사용한 데이터 캐싱으로 조회 API성능 향상시키기 (0) | 2023.07.29 |
| [개발] VPC 개념잡기 (0) | 2023.07.27 |